

去除过短或者过长训练数据在机器学习中,去除过短或过长的训练数据通常是为了提高模型的性能和稳定性。以下是具体的原因:
质量控制
过短的文本:
可能包含太少的信息,无法提供足够的上下文。
可能是噪音或无用的内容,如单个字符或单词。
过长的文本:
可能包含冗余信息或噪音。
处理起来资源消耗较大,增加计算开销。
计算效率
过长的文本:
需要更多的计算资源和时间。
可能导致内存不足或训练时间过长。
模型训练稳定性
过短的文本:
可能导致模型过拟合,无法泛化到更长或更复杂的句子。
模型可能学不到有用的特征。
过长的文本:
可能导致模型在训练时遇到梯度消失或爆炸的问题。
增加模型的复杂性,可能需要更复杂的架构来处理。
数据均衡性
去除过短或过长的文本有助于确保训练数据的长度分布更加均衡,避免模型对特定长度的文本过度拟合。
一致性和可解释性
保持数据长度在一个合理的范围内,可以提高模型预测结果的一致性和可解释性。
下面是我去除过短或者过长训练数据的代码
1234567891011import pandas as pd# 读取CSV文件data = pd.read ...
数据采集后的文本并不全是中文的,这很正常。我下一步对这部分文本数据进行了翻译,实现方法是通过DeepL这个工具api用python代码实现。不过要订阅申请DeepL的api密钥。
翻译数据结构知识数据:
12345678910111213141516171819202122232425262728293031323334353637import pandas as pdimport deepl# DeepL API认证密钥auth_key = ""translator = deepl.Translator(auth_key)# 读取XLSX文件data = pd.read_csv('ds.xlsx')# 定义一个标志位,用于指示是否停止翻译stop_translation = False# 翻译文本的函数,从英文翻译成中文def translate_to_chinese(text): global stop_translation if stop_translation: return text # 如果已经出现异常, ...
前面从广义数据的角度对数据集进行了处理,但是没有考虑到大模型的角度。在和负责大模型部分的同学沟通后,进一步对数据进行了处理,使其更贴合大规模预训练模型。通过一番查找对比,我在这里选择了llm_corpus_quality这个项目。
llm_corpus_quality集成了包含清洗、敏感词过滤、广告词过滤、语料质量自动评估等功能在内的多个数据处理工具与算法,为中文AI大模型提供安全可信的主流数据。项目采用java实现,完整项目见https://github.com/jiangnanboy/llm_corpus_quality
llm_corpus_quality支持以下特性:
规则清洗
敏感词过滤
广告过滤
去重
质量评估
处理流程如下
大模型训练语料清洗流程,共包括4个阶段5个模块:
语料清洗规则过滤:通常经过格式转换后的json文件仍存在很多问题,不能直接用于构建训练数据集。通常会以句子或篇章作为过滤单位,通过检测句子或篇章内是否含有大量的怪异符号、是否存在html网页标签等来判断文本是否为合格文本。
敏感词过滤器:利用自动机,过滤色情、赌博、部分低质量广告等内容的文本。
...
在大模型训练中,数据集划分、数据增强和数据可视化是至关重要的步骤,确保模型训练的有效性、可靠性和可解释性。下面是对这三个方面的具体实现方法的详细说明。
数据集划分:合理划分训练、验证和测试集
比例划分:
常用的划分比例是70%用于训练,15%用于验证,15%用于测试。具体比例可以根据数据集的规模和任务的需求进行调整。
随机划分:
使用随机数生成器确保数据集划分的随机性,避免样本顺序导致的偏差。
分层抽样:
在分类任务中,确保各类样本在训练、验证和测试集中的比例一致,可以使用分层抽样。
时间序列数据划分:
在时间序列数据中,按照时间顺序划分数据,确保训练集早于验证集,验证集早于测试集。
这里我使用随机划分,使用sklearn.model_selection.train_test_split函数实现:
1234from sklearn.model_selection import train_test_splittrain_data, test_data = train_test_split(data, test_size=0.3, random_state=42)train ...
在大模型训练中,数据分析是确保模型性能和训练效率的关键步骤。通过对训练数据进行全面的分析,可以发现潜在的问题和优化空间,提高模型的整体效果。以下是数据分析过程中需要重点关注的方面及其要点:
数据质量
准确性:检查数据是否有错误、错别字或不正确的标签。错误的数据会误导模型学习,降低其准确性。
完整性:确保数据集的完整性,避免缺失值或不完整的样本。缺失数据可能导致训练偏差。
数据分布
类别分布:分析分类任务中的类别分布,确保数据集中的类别分布均衡。如果类别不均衡,模型可能会偏向多数类别。
特征分布:对于回归或其他任务,检查特征的分布情况,确保没有异常值或过度偏斜的分布。
数据多样性
文本多样性:在NLP任务中,检查文本的多样性,包括词汇、句法结构和主题。多样性高的数据集有助于提高模型的泛化能力。
样本多样性:确保数据集中包含足够多样的样本,以覆盖不同的场景和情况。
文本长度
长度分布:分析文本长度的分布情况,确定合适的最大长度和最小长度。这有助于设定模型输入的最大序列长度,优化资源使用。
截断和填充:研究需要截断和填充的样本比例,确保截断和填充策略不会显著影响 ...
我们组的项目是基于大模型的知识问答教育系统,我在前期的任务是数据采集和处理清洗,以便于构建数据集训练大模型。
基于调查研究,我对于数据收集的关键点做出了以下归纳。
准确性:确保数据来源可靠,内容准确无误。错误的信息会导致模型输出错误答案,影响用户体验和教育效果。
更新性:确保数据是最新的,特别是对于动态变化的领域,如科技、法律等。
教育层次:覆盖从基础教育到高等教育的内容,适应不同学习阶段的用户需求。
结构化数据:优先选择结构化数据(如数据库、表格),便于处理和分析。
隐私保护:确保用户数据的匿名化处理,避免泄露个人信息。
合规性:遵守数据保护法律法规,如GDPR等,确保数据收集和使用过程中的合法合规性。
在开始的时候,我准备从百度百科、csdn等知识网站上收集数据,但是我发现这些网站上的数据质量良莠不齐,有的甚至有常识性错误,难以在爬取的时候进行分辨;并且这些数据的格式不一致,在后期处理的时候会造成麻烦,于是放弃。
然后我找到了Hugging Face 的 Datasets 库,这个库提供了大量预构建的数据集,涵盖了广泛的任务和领域,包括文本分类、情感分析、机器翻译、 ...

记录我大三下学期网络安全课程的作业及实验
作业要求作业目的
试用iptables命令的基本参数和配置功能,为其他实验项目准备;
练习git提交作业的方法
任务内容在自己的笔记本机器上,
使用vmware建立linux虚拟机实验环境,
先执行“iptables -F”清除可能已有的规则,
然后自己设计实验步骤和操作命令,通过检查“五元组”实现防火墙的基本功能,包括但不限于:
关闭或开放某个服务(端口)
关闭或开放某个主机(ip)
关闭或开放某个协议
其他配置功能
进阶功能:可选
部署和测试NAT功能
试用Nftables/nft
git提交撰写md格式或doc格式(不是docx格式)完成报告,提交到git。
DDL下次课(3.20)之前,git自动记录提交时间。
报告另起文档,格式可以采用技术博客风格,或者学院实验报告模板。
实验内容储备知识
在进行实验前,我先对iptables的知识进行了回顾和查阅拓展,对于其概念和用法有了更清晰的认识。
什么是 iptables?iptables 是一个用于配置 Linux 内核中 IPv4 数据包过滤器和网络地址转 ...
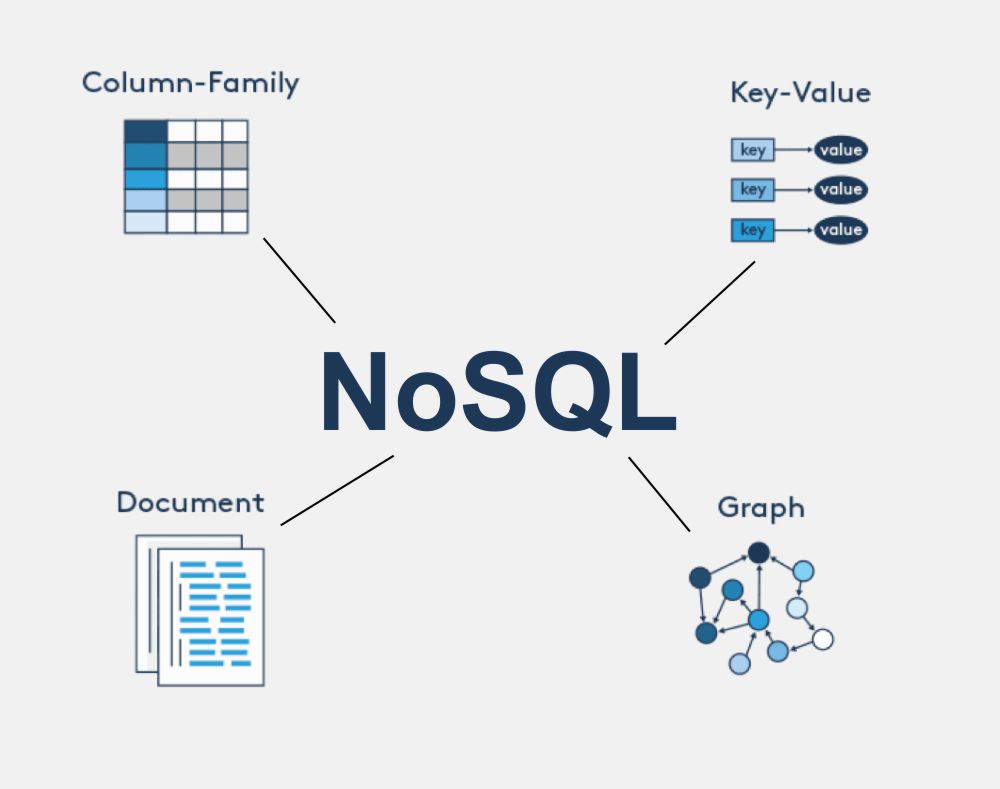
1.各种aaS2.传统ACID原子性:undolog ——在SQL执行前先于数据持久化到磁盘
持久性:都要过磁盘IO(巨大开销)——引入BufferPool机制
隔离性:隔离级别越高开销越大,同时并发程度下降
一致性:一致性是事务追求的最终目标,前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性
支持事务就意味着ACID
3.why NoSQL关系型数据库瓶颈在上面可以看到,传统数据库为了保证其ACID特性开销是相当大的,几乎所有操作都要到磁盘I/O当中,因此在高并发条件下,磁盘I/O就很容易导致性能瓶颈。【最终表现是在高并发条件下读写慢,即使有各类缓冲池存在,(设计初衷不同,对内存的优化不够好)】
此外,在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
对网站来说, ...

这门课知识体系实在很杂,涉及到大数据、sql&nosql、机器学习很多领域,而且深度不一,浅到概念深到算法原理,整理起来实在麻烦。于是秉承着极简的理念整理了这份概念文档,应付考试绰绰有余了,对某个点感兴趣的自行搜索。
第一二讲 引言总体上是概论部分,可能考的也就名词解释了,总结如下:
什么是大数据,大数据的界限,4V大数据是一种数据规模大到 在数据的获取管理,存储处理,分析计算都远远超过传统数据库软件工具处理范围的 数据集合。
大数据的界限是PB
4V: 体量巨大、速度极快(高实时性)、模态多样、价值密度低(但商业价值高)
什么是数据科学 基于传统的数学,统计学的理论和方法,运用计算机技术进行大规模的数据计算,分析,应用的学科
数据处理的一般步骤是什么 采集,表示与存储,预处理(清洗,集成等),建模分析,可视化,决策
第四五讲 数据采集与整理数据预处理基本方法:数据清理,数据集成,数据变换,数据规约
why预处理因为有脏数据,在数据挖掘工作中,脏数据是指不完整、含噪声、不一致的数据
why脏数据?
不完整,有些数据属性的值丢失或不确定;缺失必要数据,例:缺失学生成绩
不准 ...

本文档是根据任课老师所给提纲及课件等资料进行整理的,对于名词解释和简答题基本做到了全覆盖。但判断和选择题非常灵活,这份文档就显得不够用了。
标题后带*号的为次重点
复习建议:1.按照老师纲要整理知识点,全文背诵。2.注意对概念的理解,应对选择判断
第一章 软件工程概述1.1软件工程(SE)的定义、目的、方法及作用定义:在将有关软件开发与应用的概念科学体系化的基础上,研究如何有计划、有效率、 经济地开发和利用能在计算机上正确运行的软件理论和技术工程的方法学,以及一些开发和维护软件的方法、过程、原则等。它是一个系统工程,既有对技术问题的综合分析,也有对开发过程和参与者的管理。
目的:以计算机科学理论和计算机功能为基础,通过对要解决问题的本质的了解,采用相应的工具和技术,实现设计方案,推出高质量的软件产品。在给定成本、进度的前提下,开发出具有适用性、有效性、可修改性、可靠性、可理解性、可维护性、可重用性、可移植性、可追踪性、可互操作性和满足用户需求的软件产品。追求这些目标有助于提高软件产品的质量和开发效率,减少维护的困难。
方法:面向对象模式,结构化模式,基于过程的模式等。
作用:付 ...


