
项目实训个人周报合集

项目实训个人周报合集
琴生4.14
我们组的项目是基于大模型的知识问答教育系统,我在前期的任务是数据采集和处理清洗,以便于构建数据集训练大模型。
基于调查研究,我对于数据收集的关键点做出了以下归纳。
准确性:确保数据来源可靠,内容准确无误。错误的信息会导致模型输出错误答案,影响用户体验和教育效果。
更新性:确保数据是最新的,特别是对于动态变化的领域,如科技、法律等。
教育层次:覆盖从基础教育到高等教育的内容,适应不同学习阶段的用户需求。
结构化数据:优先选择结构化数据(如数据库、表格),便于处理和分析。
隐私保护:确保用户数据的匿名化处理,避免泄露个人信息。
合规性:遵守数据保护法律法规,如GDPR等,确保数据收集和使用过程中的合法合规性。
在开始的时候,我准备从百度百科、csdn等知识网站上收集数据,但是我发现这些网站上的数据质量良莠不齐,有的甚至有常识性错误,难以在爬取的时候进行分辨;并且这些数据的格式不一致,在后期处理的时候会造成麻烦,于是放弃。
然后我找到了Hugging Face 的 Datasets 库,这个库提供了大量预构建的数据集,涵盖了广泛的任务和领域,包括文本分类、情感分析、机器翻译、问答、对话系统等。这些数据集经过整理和优化,便于用户直接使用。这个库还可以通过简单的 API 调用轻松下载和加载数据集,无需手动下载和处理数据文件,比较方便。
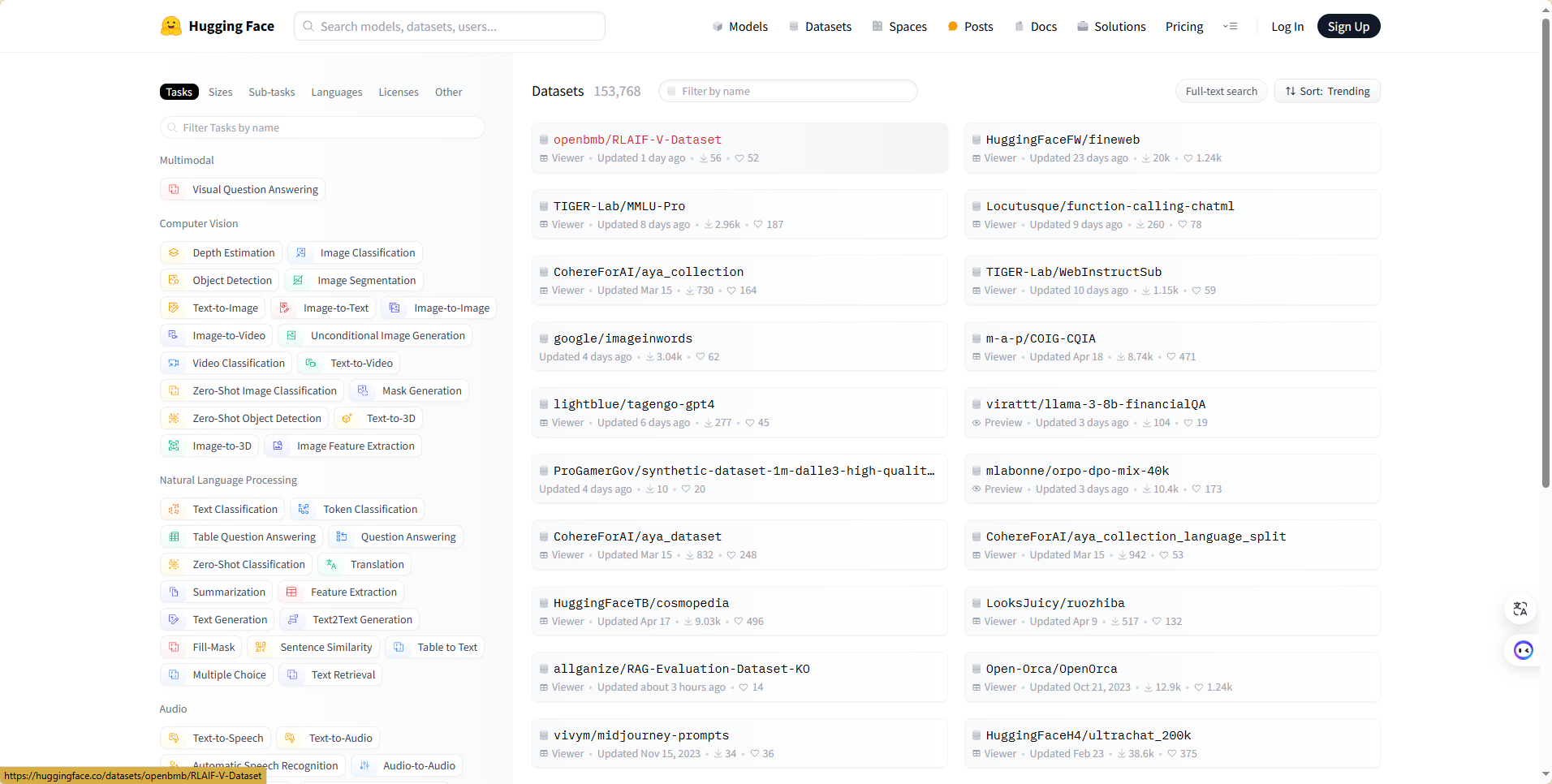
于是我决定在这里进行数据的收集。因为我们的项目是问答系统,所以我筛选了可能用得到的QA数据集。以下是我认为能用到的数据集,供给大模型训练。
医疗:https://huggingface.co/datasets/lavita/medical-qa-datasets?row=15
https://huggingface.co/datasets/blinoff/medical_qa_ru_data?row=7
https://huggingface.co/datasets/medalpaca/medical_meadow_medqa
中医:https://huggingface.co/datasets/FreedomIntelligence/huatuo_knowledge_graph_qa
中文综合:https://huggingface.co/datasets/m-a-p/COIG-CQIA
博客节目:https://huggingface.co/datasets/wavpub/JinJinLeDao_QA_Dataset
哲学:https://huggingface.co/datasets/sayhan/strix-philosophy-qa/viewer/default/train?p=1337&row=133777
心理健康:https://huggingface.co/datasets/Amod/mental_health_counseling_conversations?row=7
小学数学:https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k
计算机相关
数学:https://huggingface.co/datasets/math-ai/StackMathQA
https://huggingface.co/datasets/flytech/python-codes-25k
sql编程:https://huggingface.co/datasets/b-mc2/sql-create-context
代码指令:https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-Instruction?row=38
https://huggingface.co/datasets/m-a-p/Code-Feedback/viewer/default/train?p=663&row=66310
论文NLP:https://huggingface.co/datasets/allenai/qasper?row=0
stackExchange:https://huggingface.co/datasets/lvwerra/stack-exchange-paired?row=16
综合包括computer science:https://huggingface.co/datasets/MMMU/MMMU/viewer/Computer_Science/test?row=2
https://huggingface.co/datasets/cais/mmlu/viewer/college_computer_science?row=29
https://huggingface.co/datasets/ikala/tmmluplus/viewer/computer_science/test
然后我在kaggle网站上找到了一个与我们项目适配程度较大的数据集,是关于计算机理论知识的问答集:
https://www.kaggle.com/datasets/mujtabamatin/computer-science-theory-qa-dataset
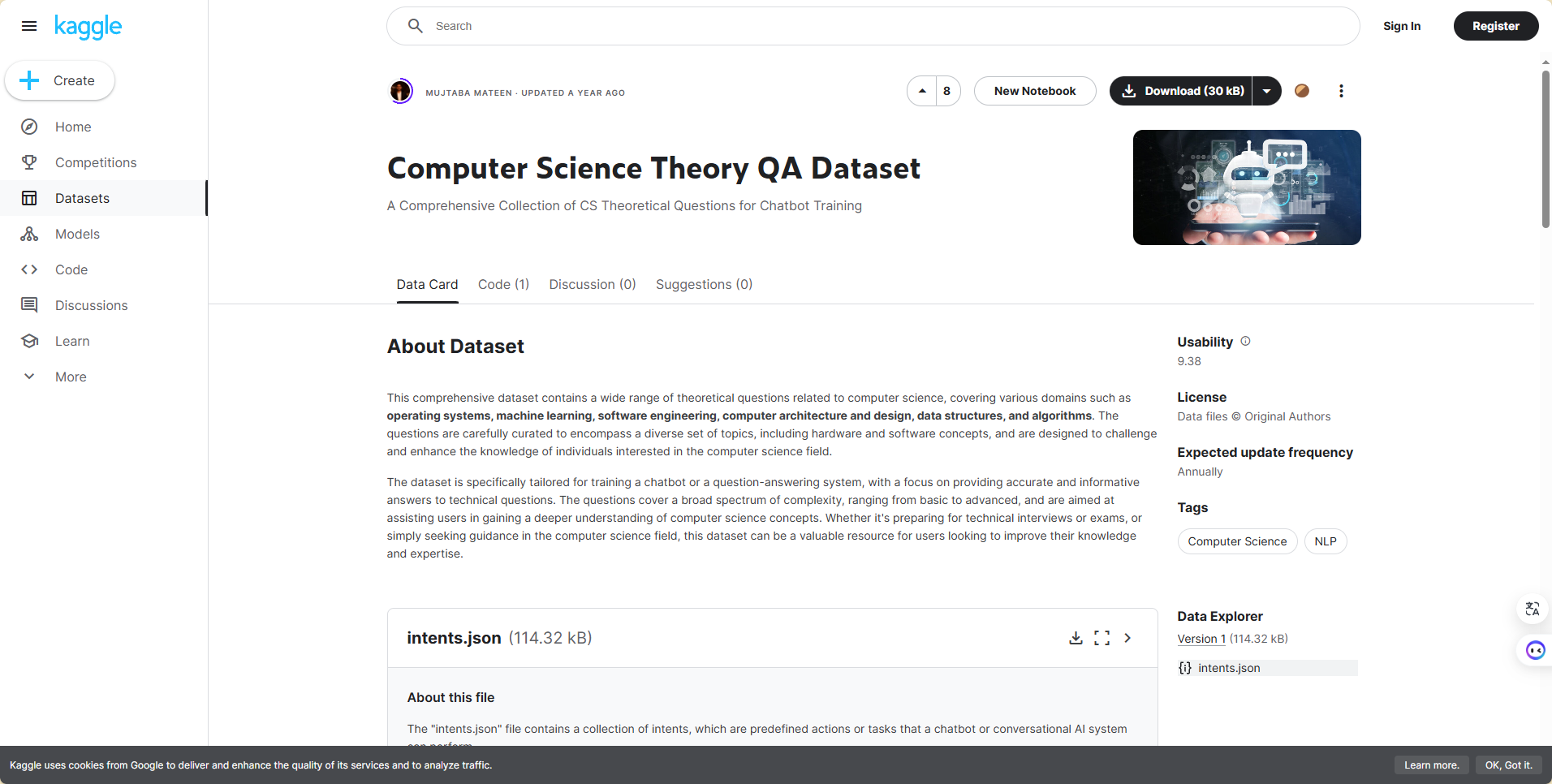
结合做大模型相关工作的同学的反馈,我选取了上述中的几个数据集,整理成了csv文件,以便于后续的数据清洗等工作。
4.23
在大模型训练中,数据分析是确保模型性能和训练效率的关键步骤。通过对训练数据进行全面的分析,可以发现潜在的问题和优化空间,提高模型的整体效果。以下是数据分析过程中需要重点关注的方面及其要点:
- 数据质量
- 准确性:检查数据是否有错误、错别字或不正确的标签。错误的数据会误导模型学习,降低其准确性。
- 完整性:确保数据集的完整性,避免缺失值或不完整的样本。缺失数据可能导致训练偏差。
- 数据分布
- 类别分布:分析分类任务中的类别分布,确保数据集中的类别分布均衡。如果类别不均衡,模型可能会偏向多数类别。
- 特征分布:对于回归或其他任务,检查特征的分布情况,确保没有异常值或过度偏斜的分布。
- 数据多样性
- 文本多样性:在NLP任务中,检查文本的多样性,包括词汇、句法结构和主题。多样性高的数据集有助于提高模型的泛化能力。
- 样本多样性:确保数据集中包含足够多样的样本,以覆盖不同的场景和情况。
- 文本长度
- 长度分布:分析文本长度的分布情况,确定合适的最大长度和最小长度。这有助于设定模型输入的最大序列长度,优化资源使用。
- 截断和填充:研究需要截断和填充的样本比例,确保截断和填充策略不会显著影响数据质量。
- 数据预处理
- 清洗和标准化:对数据进行必要的清洗和标准化处理,如去除噪声、统一格式和处理特殊字符。
- 去重:检查并去除重复的样本,避免模型在重复数据上过度拟合。
观察发现,QA数据集中有空格、“答:”、乱码等不需要的字样,于是进行处理。
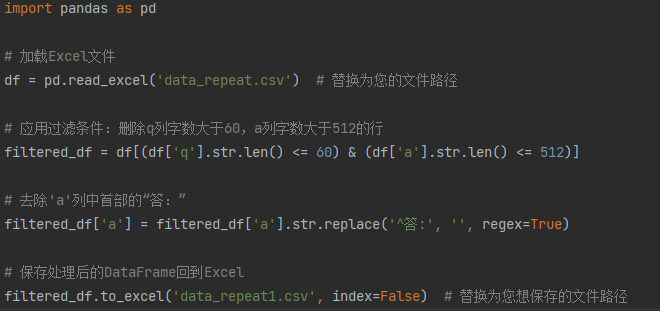
通过上述模版代码,去除了数据集中”答:”的字样,然后如法炮制,将空格和乱码都进行了去除和清洗。清理完后的部分数据如下图。

可以观察到,数据的结构比较清晰,q列是问题,a列是答案,并且数据中的空格、乱码等已经被去除。
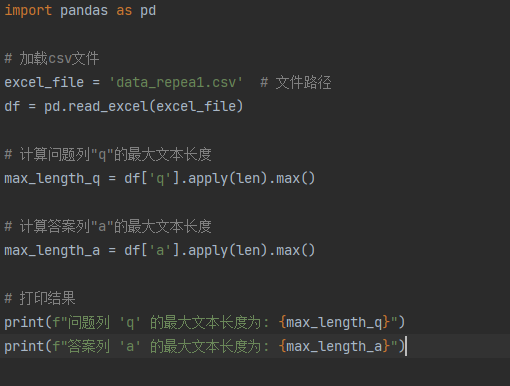
下面我进行了数据分析,主要是分析了文本长度。文本长度在大模型训练中很重要,主要有以下几点。
丰富的上下文:较长的文本通常包含更多的信息和上下文,有助于模型理解复杂的语义关系和捕捉长距离依赖。
过长文本的挑战:处理过长的文本可能导致模型过拟合或者捕捉到过多无关信息,反而可能降低模型性能。需要找到一个平衡点,既包含足够的信息,又不过多冗余。
最大长度设定:在训练过程中,通常会设定一个最大文本长度,超过该长度的文本会被截断。这种策略需要权衡信息完整性和计算资源。
任务特定需求:不同任务对文本长度的需求不同。例如,句子分类任务可能不需要很长的文本,而文档摘要生成则需要处理更长的文本。
微调阶段:在微调阶段,根据具体任务调整文本长度,可以优化模型性能和资源利用效率。
分析文本长度的代码如下。
5.06
在大模型训练中,数据集划分、数据增强和数据可视化是至关重要的步骤,确保模型训练的有效性、可靠性和可解释性。下面是对这三个方面的具体实现方法的详细说明。
数据集划分:合理划分训练、验证和测试集
比例划分:
常用的划分比例是70%用于训练,15%用于验证,15%用于测试。具体比例可以根据数据集的规模和任务的需求进行调整。
随机划分:
使用随机数生成器确保数据集划分的随机性,避免样本顺序导致的偏差。
分层抽样:
在分类任务中,确保各类样本在训练、验证和测试集中的比例一致,可以使用分层抽样。
时间序列数据划分:
在时间序列数据中,按照时间顺序划分数据,确保训练集早于验证集,验证集早于测试集。
这里我使用随机划分,使用sklearn.model_selection.train_test_split函数实现:
1 | from sklearn.model_selection import train_test_split |
数据增强:同义词替换、回译、随机删除
1.同义词替换
随机选择句子中的词,替换为其同义词。
这里我使用NLTK实现:
1 | from nltk.corpus import wordnet |
2.回译:
将文本翻译成另一种语言,再翻译回来,以生成新的文本。
我这里使用谷歌的翻译API(Google Translate API)实现:
1 | from googletrans import Translator |
3.随机删除:
随机删除句子中的一些词,生成新的变体。
实现如下:
1 | import random |
数据可视化:文本数据可视化
词频统计:使用词云(Word Cloud)展示高频词。
1 | from wordcloud import WordCloud |
5.19
数据采集后的文本并不全是中文的,这很正常。我下一步对这部分文本数据进行了翻译,实现方法是通过DeepL这个工具api用python代码实现。不过要订阅申请DeepL的api密钥。
翻译数据结构知识数据:
1 | import pandas as pd |
下面给出代码解释:
- 导入库
import pandas as pd:导入Pandas库,常用于数据处理和分析。import deepl:导入DeepL库,用于实现文本的机器翻译。
- 设置DeepL API密钥
auth_key = "DeepL API密钥":这里需要替换为DeepL API密钥,用于身份认证和访问翻译服务。
- 创建DeepL翻译器实例
translator = deepl.Translator(auth_key):使用提供的API密钥创建一个DeepL翻译器实例。
- 加载数据
data = pd.read_csv('train.parquet'):使用Pandas的read_csv函数加载csv格式的文件。
- 定义翻译函数
translate_to_chinese(text):这是一个函数,输入参数是文本(英文),输出是翻译后的文本(中文)。global stop_translation:使用global关键字声明stop_translation,这允许函数内部修改全局变量。if stop_translation:如果stop_translation为真(表示已经发生翻译错误),则函数直接返回原文本,不进行翻译。try-except块:尝试使用DeepL翻译器翻译文本,如果发生异常(如网络问题、API限制等),则捕获异常,打印错误信息,并设置stop_translation为真,之后的所有翻译调用将直接返回原文。
- 应用翻译函数到数据列
data['question'] = data['question'].apply(translate_to_chinese):将translate_to_chinese函数应用于数据框data中名为question的列。这将逐行将英文指令翻译成中文。
- 显示翻译后的数据
print(data.head()):打印翻译后的数据框的前几行,用于检查翻译结果。
- 保存翻译后的数据
data.to_csv('translated_train.csv', index=False):将翻译后的数据保存到一个名为translated_train.csv的CSV文件,index=False参数表示不保存行索引。
翻译java知识数据:
1 | import pandas as pd |
翻译操作系统知识数据:(这里源文件是parquet类型)
1 | import pandas as pd |
翻译计网知识数据:(这里源文件是俄语版,方法略有改动)
1 | import pandas as pd |
5.26
去除过短或者过长训练数据
在机器学习中,去除过短或过长的训练数据通常是为了提高模型的性能和稳定性。以下是具体的原因:
- 质量控制
过短的文本:
- 可能包含太少的信息,无法提供足够的上下文。
- 可能是噪音或无用的内容,如单个字符或单词。
过长的文本:
- 可能包含冗余信息或噪音。
- 处理起来资源消耗较大,增加计算开销。
- 计算效率
过长的文本:
- 需要更多的计算资源和时间。
- 可能导致内存不足或训练时间过长。
- 模型训练稳定性
过短的文本:
- 可能导致模型过拟合,无法泛化到更长或更复杂的句子。
- 模型可能学不到有用的特征。
过长的文本:
- 可能导致模型在训练时遇到梯度消失或爆炸的问题。
- 增加模型的复杂性,可能需要更复杂的架构来处理。
- 数据均衡性
去除过短或过长的文本有助于确保训练数据的长度分布更加均衡,避免模型对特定长度的文本过度拟合。
- 一致性和可解释性
保持数据长度在一个合理的范围内,可以提高模型预测结果的一致性和可解释性。
下面是我去除过短或者过长训练数据的代码
1 | import pandas as pd |
- 读取CSV文件:使用
pd.read_csv()函数读取名为data.csv的文件 - 过滤数据
- 使用Pandas的字符串方法
.str.len()来计算每一行中question和answer列的长度。 - 使用布尔索引过滤出满足所有条件的行:
- 问题列的长度至少为5个字符且不超过50个字符。
- 答案列的长度至少为50个字符且不超过512个字符。
- 使用Pandas的字符串方法
- 保存过滤后的数据:使用
to_csv()方法将过滤后的数据保存到一个名为filtered_data.csv的新文件中。设置index=False参数来避免写入行索引到文件。
删除相似的问题或者相似的答案
在大模型训练中,删除相似的问题或相似的答案有以下几个主要原因:
- 减少数据冗余
相似的问题和答案:
- 会导致数据集中存在大量重复信息。
- 增加数据量但不提供新的有价值的信息。
通过删除相似的样本,可以减少数据冗余,使模型更专注于学习多样化和有代表性的信息。
- 提高训练效率
减少冗余数据:
- 可以显著减少训练时间和计算资源的消耗。
- 使模型训练更高效,因为训练时不需要反复处理相似的信息。
- 防止过拟合
相似的问题和答案:
- 可能导致模型对某些特定模式过拟合。
- 模型可能会记住这些重复的样本,而不是学会如何处理更多样化的数据。
删除相似的样本有助于提高模型的泛化能力,使其在面对新数据时表现更好。
- 增强模型的多样性学习
多样化数据:
- 使模型能够学习到更广泛的模式和特征。
- 提高模型在不同情境下的表现能力。
删除相似的样本可以确保模型接触到更多样化的训练数据,从而提高模型的鲁棒性和应对不同情况的能力。
- 改善数据集质量
清理数据集:
- 可以去除那些重复或者几乎相同的问答对,提升数据集的整体质量。
- 有助于确保数据集中的每个样本都提供有价值的训练信息。
高质量的数据集有助于模型更有效地学习和推理。
下面是我的代码
1 | import pandas as pd |
相似度计算函数
- 使用
SequenceMatcher函数比较两个字符串的相似度。这个函数返回一个介于0和1之间的数值,表示两个字符串的相似度百分比。
- 使用
读取CSV文件
- 使用
pd.read_csv()读取CSV文件。
- 使用
初始化索引列表
- 使用一个集合
indices_to_drop来存储需要删除的行索引。使用集合可以避免重复添加同一索引。
- 使用一个集合
双重循环比较每行
- 用双重循环遍历数据框,比较每一对问题和答案。
- 如果发现问题或答案的相似度超过80%,将较后的行索引添加到
indices_to_drop集合中。
删除指定行
- 使用
DataFrame.drop方法删除所有标记为删除的行。
- 使用
保存结果
- 使用
to_csv()方法将处理后的数据保存到新的CSV文件filtered_data.csv中,index=False参数确保不保存行索引。
- 使用
这段代码将根据问题和答案的相似度过滤出唯一的行,是处理大量文本数据
6.03
前面从广义数据的角度对数据集进行了处理,但是没有考虑到大模型的角度。在和负责大模型部分的同学沟通后,进一步对数据进行了处理,使其更贴合大规模预训练模型。通过一番查找对比,我在这里选择了llm_corpus_quality这个项目。
llm_corpus_quality集成了包含清洗、敏感词过滤、广告词过滤、语料质量自动评估等功能在内的多个数据处理工具与算法,为中文AI大模型提供安全可信的主流数据。项目采用java实现,完整项目见https://github.com/jiangnanboy/llm_corpus_quality
llm_corpus_quality支持以下特性:
- 规则清洗
- 敏感词过滤
- 广告过滤
- 去重
- 质量评估
处理流程如下
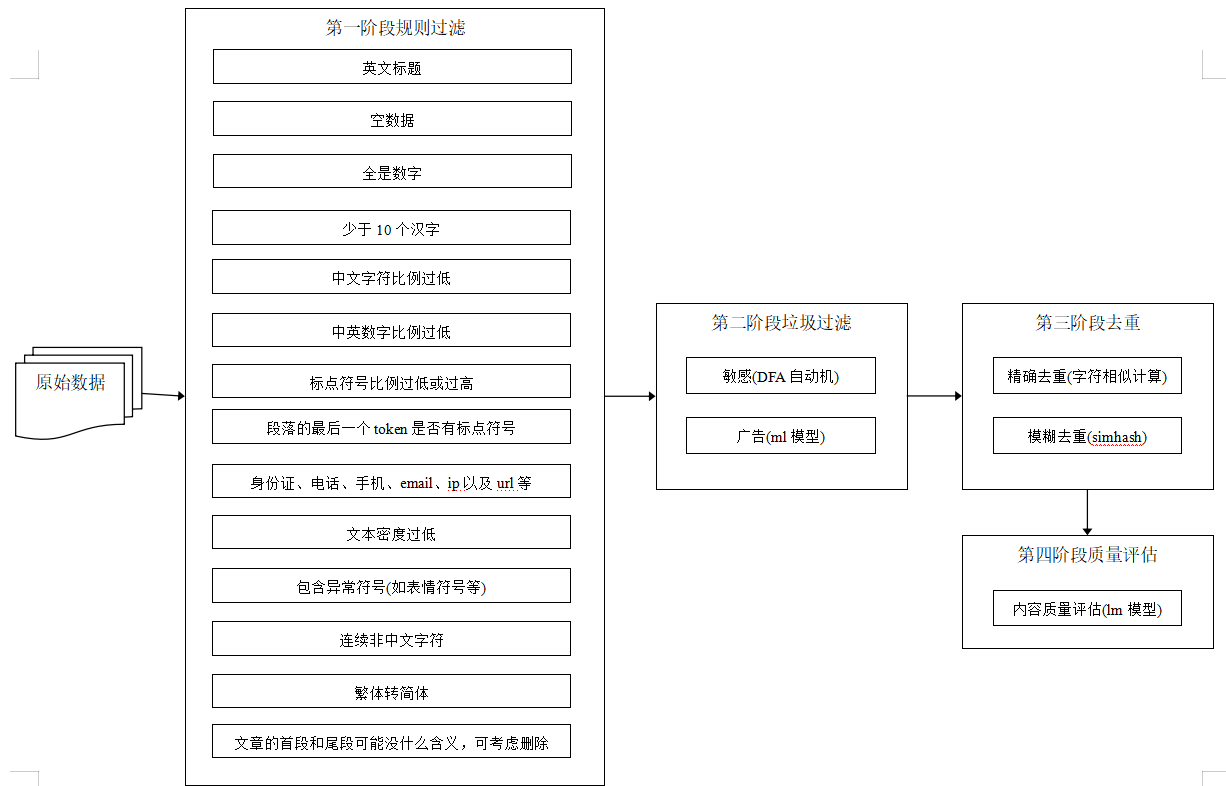
大模型训练语料清洗流程,共包括4个阶段5个模块:
- 语料清洗规则过滤:通常经过格式转换后的json文件仍存在很多问题,不能直接用于构建训练数据集。通常会以句子或篇章作为过滤单位,通过检测句子或篇章内是否含有大量的怪异符号、是否存在html网页标签等来判断文本是否为合格文本。
- 敏感词过滤器:利用自动机,过滤色情、赌博、部分低质量广告等内容的文本。
- 广告过滤:利用textcnn模型,过滤涉嫌广告内容。(见https://github.com/jiangnanboy/ad_detect_textcnn)
- 去重:利用simhash对相似文本片段进行去重。
- 质量评估:采用ngram语言模型评估的方法,对语料进行概率预估,文本质量越高的语句,困惑度ppl越低,设定一个ppl阈值,高于这个阈值为低质量语料,可过滤。
下面是作者给出的示例代码,我稍加改动,对预处理的数据集进行了适配大模型的清洗,得到了最终数据集。
1 | // hash data of corpus to deduplication (read and save) |
不过在这里,我对清洗前后的数据进行观察,发现并没有明显变化,因为原本的数据集已经是在上传者处理过后上传至平台上的。
6.11
转换为Alpaca数据集和Json格式用于模型训练和微调
之前得到了csv格式的数据集,而模型训练和微调需要用到json格式,于是进行转换。下面是代码:
1 | import pandas as pd |
- 读取CSV文件:使用Pandas读取
cleaned_translated_train.csv文件。 - 构建JSON格式数据:对于数据框中的每一行,创建一个字典,其中
instruction键对应问题列的内容,input键为空字符串,output键对应答案列的内容。 - 保存JSON数据:将构建的JSON数据列表保存到名为
data_for_training.json的文件中,使用json.dump进行序列化,保持格式化输出以提高可读性。
多个处理好的Json文件进行拼接,用于最后的Lora微调和Rag向量化
1 | import json |
- 导入所需的库:使用
json进行数据的序列化和反序列化,使用os来处理文件和目录路径。 - 设置文件目录:所有的JSON文件都放在名为
json_files的目录中。 - 读取JSON文件
- 使用
os.listdir()遍历指定目录中的所有文件。 - 检查文件扩展名是否为
.json,确保只处理JSON文件。 - 对于每个JSON文件,打开并使用
json.load()读取内容,然后将这些内容添加到all_data列表中。
- 使用
- 写入合并后的JSON数据
- 所有文件的数据被存储在
all_data列表中,该列表包含了从每个文件读取的数据。 - 使用
json.dump()将这个列表写入一个名为combined_data.json的新文件中,设置ensure_ascii=False来支持非ASCII字符,indent=4提供了格式化的输出,使得JSON文件易于阅读。
- 所有文件的数据被存储在
6.20
其他队友的大模型训练和前后端开发工作基本完成了,于是我进行了测试。
功能测试
功能测试的主要目的是验证网站的核心功能是否按预期工作,包括用户交互、数据输入、页面跳转和功能性操作。
测试过程中,主要集中在以下几个方面:
- 验证链接跳转是否正确
- 输入验证和表单提交
- 功能性测试,如搜索、提问、用户登录、密码找回等
测试环境
操作系统:Windows 10
浏览器:Microsoft Edge,火狐,Chrome
自动化测试工具:Selenium WebDriver, JUnit
自动化测试
对于某些复杂的用例,我用了自动化测试以便减轻人工工作量
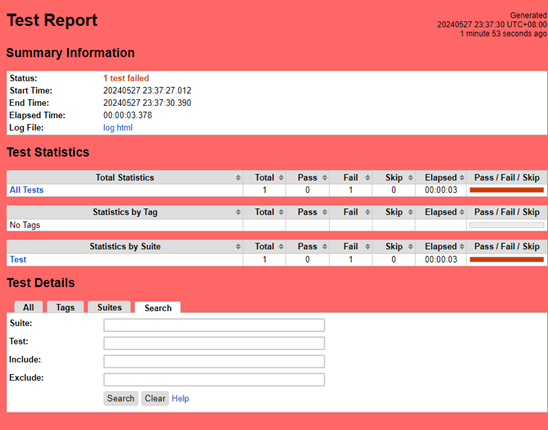
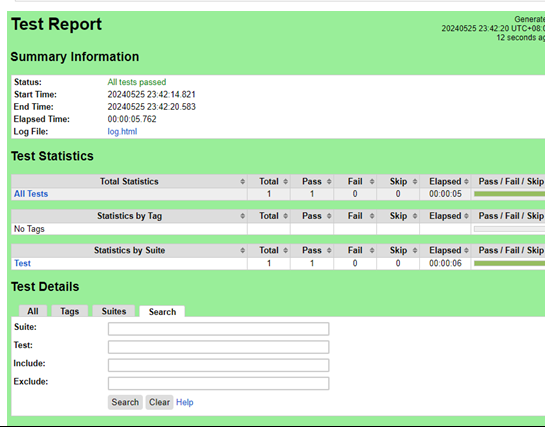
测试结果
绝大多数功能点按照预期工作,但发现了包括链接跳转错误、输入验证不严格的问题。
Bug 列表
1.输入问题时如果小于一定长度时提交会没有反应,而不是给出报错
2.输入问题时如果超出一定长度时提交会没有反应,而不是给出报错
3.前端路由跳转有时会失效
在反应给开发同学之后,修改了这些bug
性能测试
虽然网站不进行上线同时供多人使用,但性能测试也是测试的重要一环。
- 评估系统能力:性能测试通过模拟实际使用情况,对系统进行压力测试,以评估系统在不同负载条件下的性能指标,如响应时间、吞吐量、并发用户数等。
- 识别体系中的弱点:在受控的负载条件下,性能测试可以发现系统存在的性能瓶颈或弱点,为后续的修复和优化提供方向。
- 系统调优:基于性能测试的结果,可以对系统进行调优,改进性能,确保系统在实际使用中能够高效、稳定地运行。
- 验证稳定性和可靠性:通过长时间、高负载的性能测试,可以验证系统的稳定性和可靠性,确保系统在生产环境中能够持续、稳定地提供服务。
这里我选择用Jmeter进行性能测试。
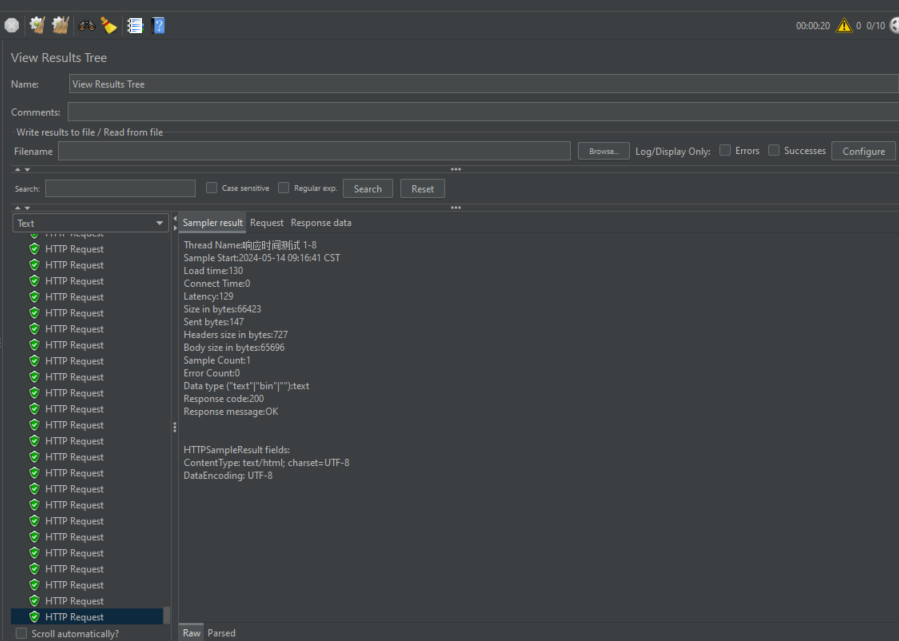
在JMeter中通过结果树监听器查看每个请求的执行结果,确认是否成功访问页面,并查看返回的HTML信息及其他相关数据。
通过监听器的聚合报告展示关键的性能指标,如平均响应时间,这是服务器响应请求所需的平均时间;最小和最大响应时间,用以观察响应时间的波动;吞吐量,即每秒处理的请求量,反映了服务器的处理能力;以及错误率,即请求失败的百分比。
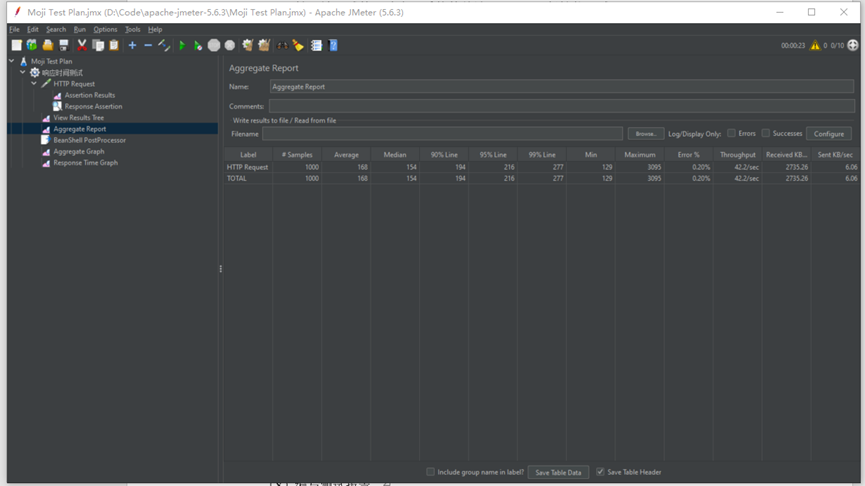
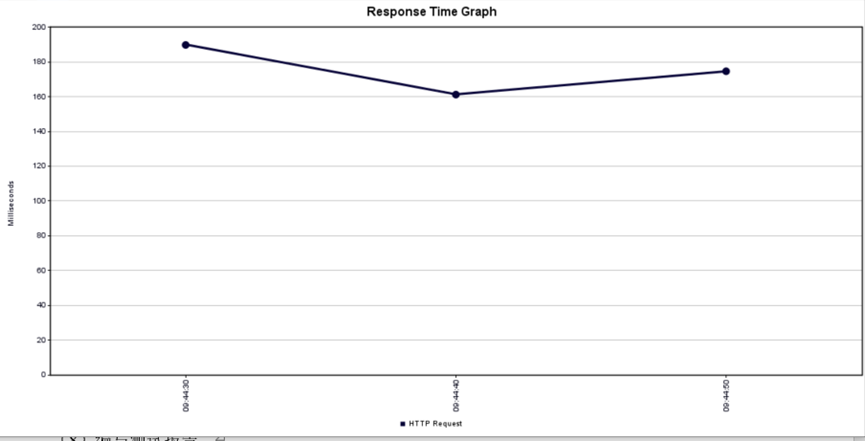
根据聚合报告的结果,在执行了1000次请求的测试中,服务器表现出良好的稳定性和效率,平均响应时间为183毫秒,但个别请求的响应时间仍有较大波动。整体来看,服务器性能稳定。








